Test DP-600
Question 1:DRAG DROP
-
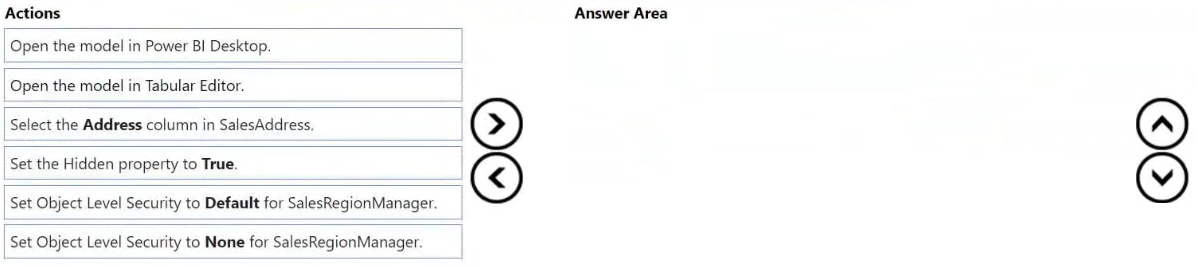
You create a semantic model by using Microsoft Power BI Desktop. The model contains one security role named SalesRegionManager and the following tables:
• Sales
• SalesRegion
• SalesAddress
You need to modify the model to ensure that users assigned the SalesRegionManager role cannot see a column named Address in SalesAddress.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Question 2:
You have a Fabric tenant that contains a warehouse.
You are designing a star schema model that will contain a customer dimension. The customer dimension table will be a Type 2 slowly changing dimension (SCD).
You need to recommend which columns to add to the table. The columns must NOT already exist in the source.
Which three types of columns should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
A.
a foreign key
B.
a natural key
C.
an effective end date and time
D.
a surrogate key
E.
an effective start date and time
Question 3:
You have a Fabric workspace named Workspace1 that contains a lakehouse named Lakehouse1.
In Workspace1, you create a data pipeline named Pipeline1.
You have CSV files stored in an Azure Storage account.
You need to add an activity to Pipeline1 that will copy data from the CSV files to Lakehouse1. The activity must support Power Query M formula language expressions.
Which type of activity should you add?
A.
Dataflow
B.
Notebook
C.
Script
D.
Copy data
Question 4:
You have a Fabric tenant.
You are creating an Azure Data Factory pipeline.
You have a stored procedure that returns the number of active customers and their average sales for the current month.
You need to add an activity that will execute the stored procedure in a warehouse. The returned values must be available to the downstream activities of the pipeline.
Which type of activity should you add?
A.
Switch
B.
Copy data
C.
Append variable
D.
Lookup
Question 5:
HOTSPOT
-
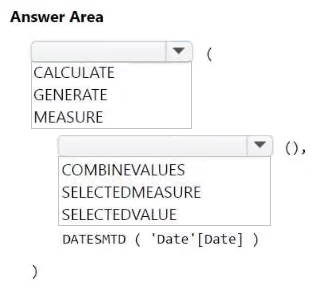
You have a Microsoft Power BI semantic model.
You plan to implement calculation groups.
You need to create a calculation item that will change the context from the selected date to month-to-date (MTD).
How should you complete the DAX expression? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Question 6:
HOTSPOT
-
You have an Azure Data Lake Storage Gen2 account named storage1 that contains a Parquet file named sales.parquet.
You have a Fabric tenant that contains a workspace named Workspace1.
Using a notebook in Workspace1, you need to load the content of the file to the default lakehouse. The solution must ensure that the content will display automatically as a table named Sales in Lakehouse explorer.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 7:
You have a semantic model named Model1. Model1 contains five tables that all use Import mode. Model1 contains a dynamic row-level security (RLS) role named HR. The HR role filters employee data so that HR managers only see the data of the department to which they are assigned.
You publish Model1 to a Fabric tenant and configure RLS role membership. You share the model and related reports to users.
An HR manager reports that the data they see in a report is incomplete.
What should you do to validate the data seen by the HR Manager?
A.
Select Test as role to view the data as the HR role.
B.
Filter the data in the report to match the intended logic of the filter for the HR department.
C.
Select Test as role to view the report as the HR manager.
D.
Ask the HR manager to open the report in Microsoft Power BI Desktop.
Question 8:
You have a Fabric tenant that contains a semantic model named Model1. Model1 uses Import mode. Model1 contains a table named Orders. Orders has 100 million rows and the following fields.

You need to reduce the memory used by Model1 and the time it takes to refresh the model.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
A.
Split OrderDateTime into separate date and time columns.
B.
Replace TotalQuantity with a calculated column.
C.
Convert Quantity into the Text data type.
D.
Replace TotalSalesAmount with a measure.
Question 9:
You have a Fabric tenant named Tenant1 that contains a workspace named WS1. WS1 uses a capacity named C1 and contains a dataset named DS1.
You need to ensure read-write access to DS1 is available by using XMLA endpoint.
What should be modified first?
A.
the DS1 settings
B.
the WS1 settings
C.
the C1 settings
D.
the Tenant1 settings
Question 10:
HOTSPOT
-
Case study
-
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
-
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
-
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment
-
Fabric Environment
-
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data
-
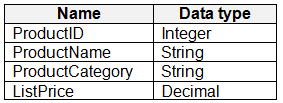
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.
The customer satisfaction data contains the following tables:
• Survey
• Question
• Response
For each survey submitted, the following occurs:
• One row is added to the Survey table.
• One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems
-
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements
-
Planned Changes
-
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
• AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
• DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
• DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
• A data store (type to be decided)
• A custom semantic model
• A default semantic model
• Interactive reports
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements
-
The data store must support the following:
• Read access by using T-SQL or Python
• Semi-structured and unstructured data
• Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
• List prices that are less than or equal to 50 are in the low pricing group.
• List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
• List prices that are greater than 1,000 are in the high pricing group.
Security Requirements
-
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
• Fabric administrators will be the workspace administrators.
• The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
• The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
• The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
• The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
• The date dimension must be available to all users of the data store.
• The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
• FabricAdmins: Fabric administrators
• AnalyticsTeam: All the members of the analytics team
• DataAnalysts: The data analysts on the analytics team
• DataScientists: The data scientists on the analytics team
• DataEngineers: The data engineers on the analytics team
• AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements
-
The data analysts must create a customer satisfaction report that meets the following requirements:
• Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
• Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
• Shows data as soon as the data is updated in the data store.
• Ensures that the report and the semantic model only contain data from the current and previous year.
• Ensures that the report respects any table-level security specified in the source data store.
• Minimizes the execution time of report queries.
You need to design a semantic model for the customer satisfaction report.
Which data source authentication method and mode should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 11:
HOTSPOT
-
Case study
-
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
-
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
-
Contoso, Ltd. is a US-based health supplements company. Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Existing Environment
-
Identity Environment
-
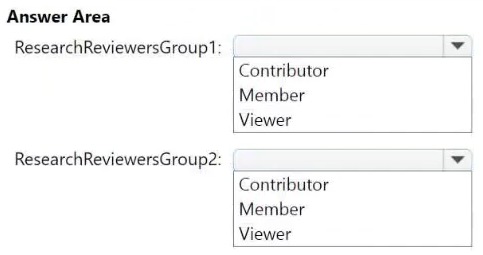
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Data Environment
-
Contoso has the following data environment:
• The Sales division uses a Microsoft Power BI Premium capacity.
• The semantic model of the Online Sales department includes a fact table named Orders that uses Import made. In the system of origin, the OrderID value represents the sequence in which orders are created.
• The Research department uses an on-premises, third-party data warehousing product.
• Fabric is enabled for contoso.com.
• An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Productline1. The data is in the delta format.
• A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Requirements
-
Planned Changes
-
Contoso plans to make the following changes:
• Enable support for Fabric in the Power BI Premium capacity used by the Sales division.
• Make all the data for the Sales division and the Research division available in Fabric.
• For the Research division, create two Fabric workspaces named Productline1ws and Productine2ws.
• In Productline1ws, create a lakehouse named Lakehouse1.
• In Lakehouse1, create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements
-
Contoso identifies the following data analytics requirements:
• All the workspaces for the Sales division and the Research division must support all Fabric experiences.
• The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
• The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
• For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
• For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
• All the semantic models and reports for the Research division must use version control that supports branching.
Data Preparation Requirements
-
Contoso identifies the following data preparation requirements:
• The Research division data for Productline1 must be retrieved from Lakehouse1 by using Fabric notebooks.
• All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements
-
Contoso identifies the following requirements for implementing and managing semantic models:
The number of rows added to the Orders table during refreshes must be minimized.
• The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements
-
Contoso identifies the following high-level requirements that must be considered for all solutions:
• Follow the principle of least privilege when applicable.
• Minimize implementation and maintenance effort when possible.
Which workspace role assignments should you recommend for ResearchReviewersGroup1 and ResearchReviewersGroup2? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Question 12:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a semantic model named Model1.
You discover that the following query performs slowly against Model1.
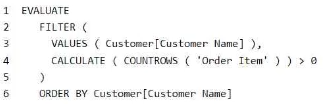
You need to reduce the execution time of the query.
Solution: You replace line 4 by using the following code:
NOT ISEMPTY ( CALCULATETABLE ( 'Order Item ' ) )
Does this meet the goal?
A.
Yes
B.
No
Question 13:
HOTSPOT
-
You have a Fabric warehouse that contains a table named Sales.Products. Sales.Products contains the following columns.
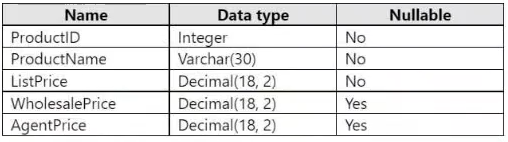
You need to write a T-SQL query that will return the following columns.

How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct answer is worth one point.

Question 14:
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Contoso, Ltd. is a US-based health supplements company. Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Existing Environment -
Identity Environment -
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Data Environment -
Contoso has the following data environment:
The Sales division uses a Microsoft Power BI Premium capacity.
The semantic model of the Online Sales department includes a fact table named Orders that uses Import made. In the system of origin, the OrderID value represents the sequence in which orders are created.
The Research department uses an on-premises, third-party data warehousing product.
Fabric is enabled for contoso.com.
An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Productline1. The data is in the delta format.
A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Requirements -
Planned Changes -
Contoso plans to make the following changes:
Enable support for Fabric in the Power BI Premium capacity used by the Sales division.
Make all the data for the Sales division and the Research division available in Fabric.
For the Research division, create two Fabric workspaces named Productline1ws and Productine2ws.
In Productline1ws, create a lakehouse named Lakehouse1.
In Lakehouse1, create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements -
Contoso identifies the following data analytics requirements:
All the workspaces for the Sales division and the Research division must support all Fabric experiences.
The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
All the semantic models and reports for the Research division must use version control that supports branching.
Data Preparation Requirements -
Contoso identifies the following data preparation requirements:
The Research division data for Productline1 must be retrieved from Lakehouse1 by using Fabric notebooks.
All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements -
Contoso identifies the following requirements for implementing and managing semantic models:
The number of rows added to the Orders table during refreshes must be minimized.
The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements -
Contoso identifies the following high-level requirements that must be considered for all solutions:
Follow the principle of least privilege when applicable.
Minimize implementation and maintenance effort when possible.
You need to refresh the Orders table of the Online Sales department. The solution must meet the semantic model requirements.
What should you include in the solution?
A.
an Azure Data Factory pipeline that executes a Stored procedure activity to retrieve the maximum value of the OrderID column in the destination lakehouse
B.
an Azure Data Factory pipeline that executes a Stored procedure activity to retrieve the minimum value of the OrderID column in the destination lakehouse
C.
an Azure Data Factory pipeline that executes a dataflow to retrieve the minimum value of the OrderID column in the destination lakehouse
D.
an Azure Data Factory pipeline that executes a dataflow to retrieve the maximum value of the OrderID column in the destination lakehouse
Question 15:
You have a Fabric tenant that contains a warehouse. The warehouse uses row-level security (RLS).
You create a Direct Lake semantic model that uses the Delta tables and RLS of the warehouse.
When users interact with a report built from the model, which mode will be used by the DAX queries?
A.
DirectQuery
B.
Dual
C.
Direct Lake
D.
Import
Question 16:
You have a Fabric tenant that contains a machine learning model registered in a Fabric workspace.
You need to use the model to generate predictions by using the PREDICT function in a Fabric notebook.
Which two languages can you use to perform model scoring? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
A.
T-SQL
B.
DAX
C.
Spark SQL
D.
PySpark
Question 17:
HOTSPOT -
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment -
Fabric Environment -
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data -
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.

The customer satisfaction data contains the following tables:
Survey -
Question -
Response -
For each survey submitted, the following occurs:
One row is added to the Survey table.
One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems -
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements -
Planned Changes -
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
A data store (type to be decided)
A custom semantic model -
A default semantic model -
Interactive reports -
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements -
The data store must support the following:
Read access by using T-SQL or Python
Semi-structured and unstructured data
Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
List prices that are less than or equal to 50 are in the low pricing group.
List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
List prices that are greater than 1,000 are in the high pricing group.
Security Requirements -
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
Fabric administrators will be the workspace administrators.
The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
The date dimension must be available to all users of the data store.
The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
AnalyticsTeam: All the members of the analytics team
DataAnalysts: The data analysts on the analytics team
DataScientists: The data scientists on the analytics team
DataEngineers: The data engineers on the analytics team
AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements -
The data analysts must create a customer satisfaction report that meets the following requirements:
Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
Shows data as soon as the data is updated in the data store.
Ensures that the report and the semantic model only contain data from the current and previous year.
Ensures that the report respects any table-level security specified in the source data store.
Minimizes the execution time of report queries.
You need to create a DAX measure to calculate the average overall satisfaction score.
How should you complete the DAX code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 18:
You are analyzing the data in a Fabric notebook.
You have a Spark DataFrame assigned to a variable named df.
You need to use the Chart view in the notebook to explore the data manually.
Which function should you run to make the data available in the Chart view?
A.
displayHTML
B.
show
C.
write
D.
display
Question 19:
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment -
Fabric Environment -
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data -
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.

The customer satisfaction data contains the following tables:
Survey -
Question -
Response -
For each survey submitted, the following occurs:
One row is added to the Survey table.
One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems -
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements -
Planned Changes -
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
A data store (type to be decided)
A custom semantic model -
A default semantic model -
Interactive reports -
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements -
The data store must support the following:
Read access by using T-SQL or Python
Semi-structured and unstructured data
Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
List prices that are less than or equal to 50 are in the low pricing group.
List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
List prices that are greater than 1,000 are in the high pricing group.
Security Requirements -
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
Fabric administrators will be the workspace administrators.
The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
The date dimension must be available to all users of the data store.
The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
AnalyticsTeam: All the members of the analytics team
DataAnalysts: The data analysts on the analytics team
DataScientists: The data scientists on the analytics team
DataEngineers: The data engineers on the analytics team
AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements -
The data analysts must create a customer satisfaction report that meets the following requirements:
Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
Shows data as soon as the data is updated in the data store.
Ensures that the report and the semantic model only contain data from the current and previous year.
Ensures that the report respects any table-level security specified in the source data store.
Minimizes the execution time of report queries.
What should you recommend using to ingest the customer data into the data store in the AnalyticsPOC workspace?
A.
a stored procedure
B.
a pipeline that contains a KQL activity
C.
a Spark notebook
D.
a dataflow
Question 20:
HOTSPOT -
You have the source data model shown in the following exhibit.

The primary keys of the tables are indicated by a key symbol beside the columns involved in each key.
You need to create a dimensional data model that will enable the analysis of order items by date, product, and customer.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 21:
You have a Fabric tenant that contains a workspace named Workspace1. Workspace1 is assigned to a Fabric capacity.
You need to recommend a solution to provide users with the ability to create and publish custom Direct Lake semantic models by using external tools. The solution must follow the principle of least privilege.
Which three actions in the Fabric Admin portal should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
A.
From the Tenant settings, set Allow XMLA Endpoints and Analyze in Excel with on-premises datasets to Enabled.
B.
From the Tenant settings, set Allow Azure Active Directory guest users to access Microsoft Fabric to Enabled.
C.
From the Tenant settings, select Users can edit data model in the Power BI service.
D.
From the Capacity settings, set XMLA Endpoint to Read Write.
E.
From the Tenant settings, set Users can create Fabric items to Enabled.
F.
From the Tenant settings, enable Publish to Web.
Question 22:
HOTSPOT -
You have a Fabric tenant.
You plan to create a Fabric notebook that will use Spark DataFrames to generate Microsoft Power BI visuals.
You run the following code.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Question 23:
HOTSPOT -
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment -
Fabric Environment -
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data -
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.

The customer satisfaction data contains the following tables:
Survey -
Question -
Response -
For each survey submitted, the following occurs:
One row is added to the Survey table.
One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems -
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements -
Planned Changes -
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
A data store (type to be decided)
A custom semantic model -
A default semantic model -
Interactive reports -
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements -
The data store must support the following:
Read access by using T-SQL or Python
Semi-structured and unstructured data
Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
List prices that are less than or equal to 50 are in the low pricing group.
List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
List prices that are greater than 1,000 are in the high pricing group.
Security Requirements -
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
Fabric administrators will be the workspace administrators.
The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
The date dimension must be available to all users of the data store.
The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
AnalyticsTeam: All the members of the analytics team
DataAnalysts: The data analysts on the analytics team
DataScientists: The data scientists on the analytics team
DataEngineers: The data engineers on the analytics team
AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements -
The data analysts must create a customer satisfaction report that meets the following requirements:
Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
Shows data as soon as the data is updated in the data store.
Ensures that the report and the semantic model only contain data from the current and previous year.
Ensures that the report respects any table-level security specified in the source data store.
Minimizes the execution time of report queries.
You need to resolve the issue with the pricing group classification.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 24:
You are the administrator of a Fabric workspace that contains a lakehouse named Lakehouse1. Lakehouse1 contains the following tables:
Table1: A Delta table created by using a shortcut
Table2: An external table created by using Spark
Table3: A managed table -
You plan to connect to Lakehouse1 by using its SQL endpoint.
What will you be able to do after connecting to Lakehouse1?
A.
Read Table3.
B.
Update the data Table3.
C.
Read Table2.
D.
Update the data in Table1.
Question 25:
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Contoso, Ltd. is a US-based health supplements company. Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Existing Environment -
Identity Environment -
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Data Environment -
Contoso has the following data environment:
The Sales division uses a Microsoft Power BI Premium capacity.
The semantic model of the Online Sales department includes a fact table named Orders that uses Import made. In the system of origin, the OrderID value represents the sequence in which orders are created.
The Research department uses an on-premises, third-party data warehousing product.
Fabric is enabled for contoso.com.
An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Productline1. The data is in the delta format.
A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Requirements -
Planned Changes -
Contoso plans to make the following changes:
Enable support for Fabric in the Power BI Premium capacity used by the Sales division.
Make all the data for the Sales division and the Research division available in Fabric.
For the Research division, create two Fabric workspaces named Productline1ws and Productine2ws.
In Productline1ws, create a lakehouse named Lakehouse1.
In Lakehouse1, create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements -
Contoso identifies the following data analytics requirements:
All the workspaces for the Sales division and the Research division must support all Fabric experiences.
The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
All the semantic models and reports for the Research division must use version control that supports branching.
Data Preparation Requirements -
Contoso identifies the following data preparation requirements:
The Research division data for Productline1 must be retrieved from Lakehouse1 by using Fabric notebooks.
All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements -
Contoso identifies the following requirements for implementing and managing semantic models:
The number of rows added to the Orders table during refreshes must be minimized.
The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements -
Contoso identifies the following high-level requirements that must be considered for all solutions:
Follow the principle of least privilege when applicable.
Minimize implementation and maintenance effort when possible.
Which syntax should you use in a notebook to access the Research division data for Productline1?
A.
spark.read.format(“delta”).load(“Tables/productline1/ResearchProduct”)
B.
spark.sql(“SELECT * FROM Lakehouse1.ResearchProduct ”)
C.
external_table(‘Tables/ResearchProduct)
D.
external_table(ResearchProduct)
Question 26:
HOTSPOT -
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment -
Fabric Environment -
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data -
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.

The customer satisfaction data contains the following tables:
Survey -
Question -
Response -
For each survey submitted, the following occurs:
One row is added to the Survey table.
One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems -
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements -
Planned Changes -
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
A data store (type to be decided)
A custom semantic model -
A default semantic model -
Interactive reports -
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements -
The data store must support the following:
Read access by using T-SQL or Python
Semi-structured and unstructured data
Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
List prices that are less than or equal to 50 are in the low pricing group.
List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
List prices that are greater than 1,000 are in the high pricing group.
Security Requirements -
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
Fabric administrators will be the workspace administrators.
The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
The date dimension must be available to all users of the data store.
The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
AnalyticsTeam: All the members of the analytics team
DataAnalysts: The data analysts on the analytics team
DataScientists: The data scientists on the analytics team
DataEngineers: The data engineers on the analytics team
AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements -
The data analysts must create a customer satisfaction report that meets the following requirements:
Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
Shows data as soon as the data is updated in the data store.
Ensures that the report and the semantic model only contain data from the current and previous year.
Ensures that the report respects any table-level security specified in the source data store.
Minimizes the execution time of report queries.
You need to assign permissions for the data store in the AnalyticsPOC workspace. The solution must meet the security requirements.
Which additional permissions should you assign when you share the data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Question 27:
HOTSPOT -
You have a Fabric tenant that contains two lakehouses.
You are building a dataflow that will combine data from the lakehouses. The applied steps from one of the queries in the dataflow is shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.

Question 28:
You have a Fabric warehouse that contains a table named Staging.Sales. Staging.Sales contains the following columns.

You need to write a T-SQL query that will return data for the year 2023 that displays ProductID and ProductName and has a summarized Amount that is higher than 10,000.
Which query should you use?
A.
B.
C.
D.
Question 29:
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment -
Fabric Environment -
Litware has been using a Microsoft Power BI tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Available Data -
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.

The customer satisfaction data contains the following tables:
Survey -
Question -
Response -
For each survey submitted, the following occurs:
One row is added to the Survey table.
One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems -
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Requirements -
Planned Changes -
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Liware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity
The following three workspaces will be created:
AnalyticsPOC: Will contain the data store, semantic models, reports pipelines, dataflow, and notebooks used to populate the data store
DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate OneLake
DataSciPOC: Will contain all the notebooks and reports created by the data scientists
The following will be created in the AnalyticsPOC workspace:
A data store (type to be decided)
A custom semantic model -
A default semantic model -
Interactive reports -
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest, transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers’ discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements -
The data store must support the following:
Read access by using T-SQL or Python
Semi-structured and unstructured data
Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SOL. queries and in the default semantic model. The following logic must be used:
List prices that are less than or equal to 50 are in the low pricing group.
List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
List prices that are greater than 1,000 are in the high pricing group.
Security Requirements -
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC.
Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
Fabric administrators will be the workspace administrators.
The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook
The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power BI reports by using the semantic models created by the analytics engineers.
The date dimension must be available to all users of the data store.
The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
FabricAdmins: Fabric administrators
AnalyticsTeam: All the members of the analytics team
DataAnalysts: The data analysts on the analytics team
DataScientists: The data scientists on the analytics team
DataEngineers: The data engineers on the analytics team
AnalyticsEngineers: The analytics engineers on the analytics team
Report Requirements -
The data analysts must create a customer satisfaction report that meets the following requirements:
Enables a user to select a product to filter customer survey responses to only those who have purchased that product.
Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected dat.
Shows data as soon as the data is updated in the data store.
Ensures that the report and the semantic model only contain data from the current and previous year.
Ensures that the report respects any table-level security specified in the source data store.
Minimizes the execution time of report queries.
Which type of data store should you recommend in the AnalyticsPOC workspace?
A.
a data lake
B.
a warehouse
C.
a lakehouse
D.
an external Hive metastore
Question 30:
Case study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Contoso, Ltd. is a US-based health supplements company. Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Existing Environment -
Identity Environment -
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Data Environment -
Contoso has the following data environment:
The Sales division uses a Microsoft Power BI Premium capacity.
The semantic model of the Online Sales department includes a fact table named Orders that uses Import made. In the system of origin, the OrderID value represents the sequence in which orders are created.
The Research department uses an on-premises, third-party data warehousing product.
Fabric is enabled for contoso.com.
An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Productline1. The data is in the delta format.
A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Requirements -
Planned Changes -
Contoso plans to make the following changes:
Enable support for Fabric in the Power BI Premium capacity used by the Sales division.
Make all the data for the Sales division and the Research division available in Fabric.
For the Research division, create two Fabric workspaces named Productline1ws and Productine2ws.
In Productline1ws, create a lakehouse named Lakehouse1.
In Lakehouse1, create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements -
Contoso identifies the following data analytics requirements:
All the workspaces for the Sales division and the Research division must support all Fabric experiences.
The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
All the semantic models and reports for the Research division must use version control that supports branching.
Data Preparation Requirements -
Contoso identifies the following data preparation requirements:
The Research division data for Productline1 must be retrieved from Lakehouse1 by using Fabric notebooks.
All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements -
Contoso identifies the following requirements for implementing and managing semantic models:
The number of rows added to the Orders table during refreshes must be minimized.
The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements -
Contoso identifies the following high-level requirements that must be considered for all solutions:
Follow the principle of least privilege when applicable.
Minimize implementation and maintenance effort when possible.
You need to ensure that Contoso can use version control to meet the data analytics requirements and the general requirements.
What should you do?
A.
Store at the semantic models and reports in Data Lake Gen2 storage.
B.
Modify the settings of the Research workspaces to use a GitHub repository.
C.
Modify the settings of the Research division workspaces to use an Azure Repos repository.
D.
Store all the semantic models and reports in Microsoft OneDrive.
Question 31:
You have a Fabric tenant that contains a warehouse.
You use a dataflow to load a new dataset from OneLake to the warehouse.
You need to add a PowerQuery step to identify the maximum values for the numeric columns.
Which function should you include in the step?
A.
Table.MaxN
B.
Table.Max
C.
Table.Range
D.
Table.Profile
Disclaimer:
The content on this webpage is collected from various internet sources. While we strive for accuracy, we cannot guarantee its completeness or correctness. Please use it with caution and conduct further research if needed. We do not claim ownership or copyright over any content. If you find any copyrighted material or content that violates laws, please contact us for removal. By accessing this webpage, you agree to these terms. Thank you for your understanding.
The content on this webpage is collected from various internet sources. While we strive for accuracy, we cannot guarantee its completeness or correctness. Please use it with caution and conduct further research if needed. We do not claim ownership or copyright over any content. If you find any copyrighted material or content that violates laws, please contact us for removal. By accessing this webpage, you agree to these terms. Thank you for your understanding.